Class 11 Maths Statistics – Get here the Notes, Question & Practice Paper of Class 11 Maths for topic Statistics Notes. Statistics Notes for Class 11 Maths are here. You can download the Statistics Notes PDF to study all the topics in this chapter. Moreover the class 11 Maths notes include chapter summary, definitions, examples, and key pointers for Statistics. Thus if you are studying class Maths (गणित), then the Statistics notes will help you easily understand the topic and ace it.
Class 11 Maths Notes for Statistics
Statistics is a critical part in the study of Maths. In India, it is taught in class. Therefore the class 11 Notes for Maths topic Statistics have been compiled by teachers and field experts. They explain the complete chapter of Statistics in one-shot. Whether you are studying the topic Statistics to complete your class syllabus, or for any competitive exam like JEE, NEET, UPSC, you can simply refer these notes to complete the chapter in one-shot!
Statistics Notes Download Link – Click Here to Download PDF
Statistics Notes for Class 11 Maths PDF
The PDF of Statistics class 11 notes is as follows. You can view the document here and also download it to use it anytime for future reference whenever you want to brush up your concepts of Maths.
Class 11 Maths Notes for Statistics View Download








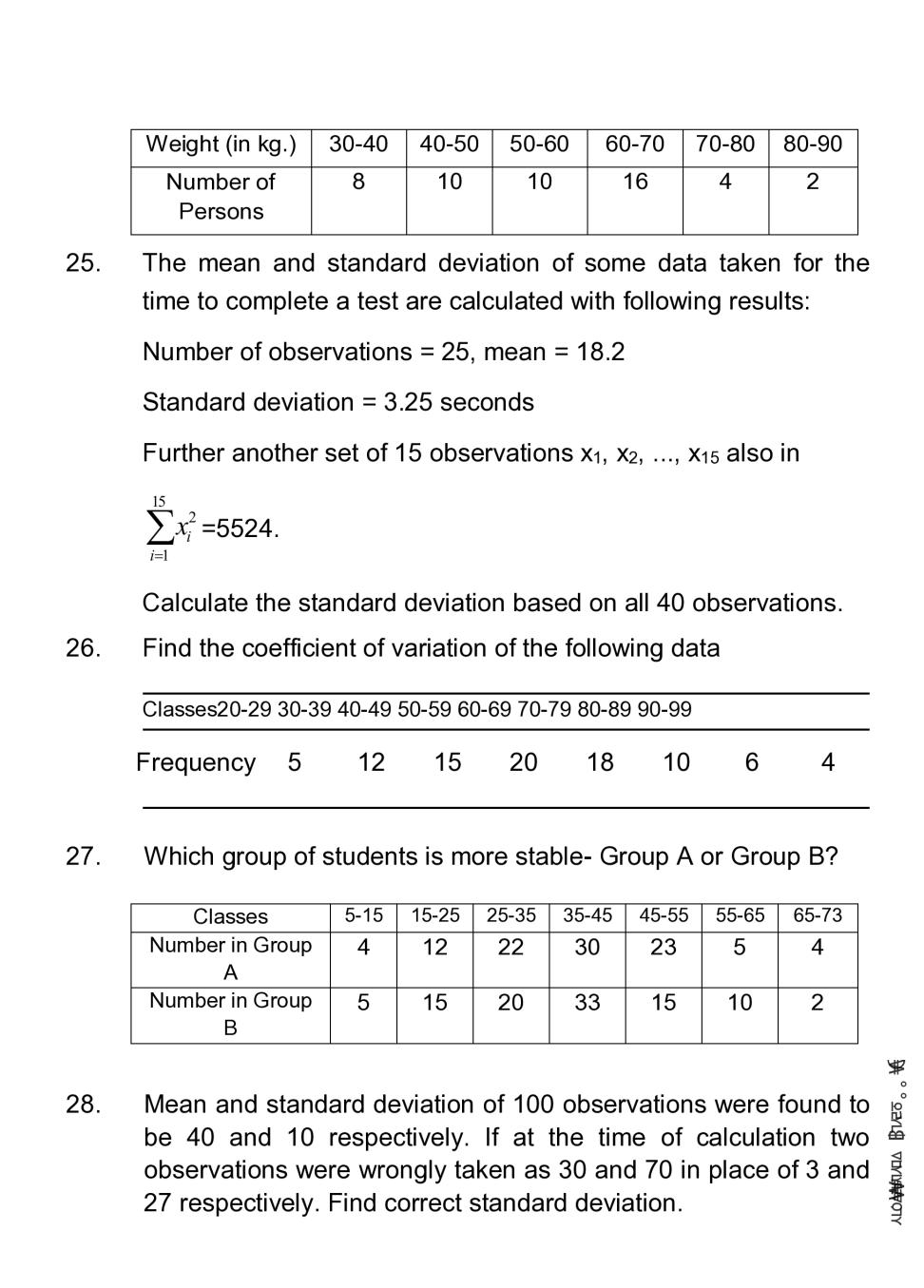


Candidates who are ambitious to qualify the Class 11 with good score can check this article for Notes, Study Material, Practice Paper. Above we provided the link to access the Notes, Important Question and Practice Paper of Class 11 Maths for topic Statistics.
All Topics Class 11 Maths Notes
Chapter wise notes for Maths (गणित) are given below.
- Binomial Theorem
- Complex Numbers and Quadratic Equations
- Conic Sections
- Introduction to Three-dimensional Coordinate Geometry
- Limits and Derivatives
- Linear Inequalities
- Mathematical Reasoning
- Permutations and Combinations
- Principle of Mathematical Induction
- Probability
- Relations and Functions
- Sequences and Series
- Sets
- Statistics
- Straight Lines
- Trigonometric Functions
Class 11 Notes for All Subjects
- Class 11 Accountancy Notes
- Class 11 Biology Notes
- Class 11 Business Studies Notes
- Class 11 Chemistry Notes
- Class 11 Economics Notes
- Class 11 English Notes
- Class 11 Geography Notes
- Class 11 Hindi Notes
- Class 11 History Notes
- Class 11 Maths Notes
- Class 11 Physical Education Notes
- Class 11 Physics Notes
- Class 11 Political Science Notes
- Class 11 Sociology Notes
NCERT Solutions for Class 11 Maths Statistics
The Statistics notes here help you solve the questions and answers. Also, you can complete the class 11 Statistics worksheet using the same. In addition you will also tackle CBSE Class 11 Maths Important Questions with these class 11 notes.
However if you still need help, then you can use the NCERT Solutions for Class 11 Maths Statistics to get all the answers. Statistics solutions contain questions, answers, and steps to solve all questions.
Notes for All Classes
Statistics Notes for Class 11 Maths – An Overview
| Name of Topic | Statistics |
| Class | 11 |
| Subject | Maths |
| All Class 11 Maths Notes | Class 11 Maths Notes |
| All Class 11 Notes | Class 11 Notes |
Class 11 Statistics Notes for All Boards
You can use the class 11 Maths notes of Statistics for all boards.
The education boards in India for which Statistics notes are relevant are – CBSE, CISCE, AHSEC, CHSE Odisha, CGBSE, HBSE, HPBOSE, PUE Karnataka, MSBSHSE, PSEB, RBSE, TBSE, UPMSP, UBSE, BIEAP, BSEB, GBSHSE, GSEB, JAC, JKBOSE, KBPE, MBOSE, MBSE, MPBSE, NBSE, DGE TN, TSBIE, COHSEM, WBCHSE.
Therefore you can refer to these notes as CBSE, CISCE, AHSEC, CHSE Odisha, CGBSE, HBSE, HPBOSE, PUE Karnataka, MSBSHSE, PSEB, RBSE, TBSE, UPMSP, UBSE, BIEAP, BSEB, GBSHSE, GSEB, JAC, JKBOSE, KBPE, MBOSE, MBSE, MPBSE, NBSE, DGE TN, TSBIE, COHSEM, WBCHSE notes for class Class 11 / Class / Maths for the topic Statistics.
To get study material, exam alerts and news, join our Whatsapp Channel.
